
Introduction: Beyond Single-Modality Data Intelligence
In the healthcare domain, we interact daily with vast and diverse data – from detailed textual medical records and sophisticated medical images to patient audio narrations and even surgical video recordings. Traditional data processing methods often struggle to effectively integrate information from these different “modalities,” limiting our ability to derive comprehensive insights. However, with the rapid advancement of artificial intelligence, a more powerful and flexible data processing paradigm is emerging: the combination of Any-to-Any models and Multimodal Large Language Models (Multimodal LLMs).
At BIT Research Alliance, we are actively exploring and advancing the research and application of these sophisticated architectures, aiming to revolutionize how medical data is processed and unlock its immense underlying value.
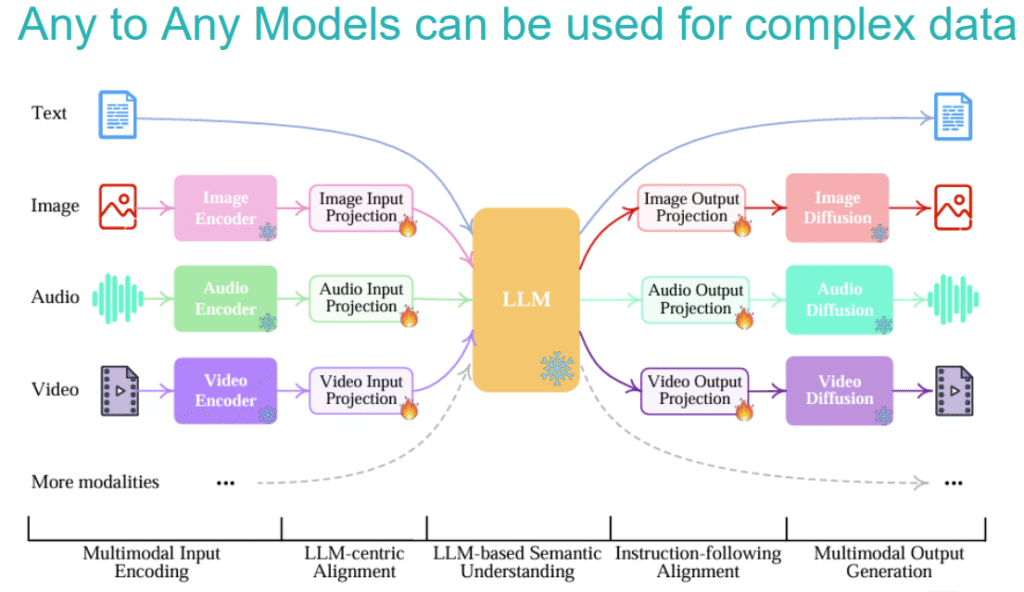
What is an Any-to-Any Model Architecture?
The core concept of an “Any-to-Any” model is to break down the barriers between data modalities. Traditional models are often specific input-output combinations like “Text-to-Text” or “Image-to-Text.” In contrast, Any-to-Any models strive for a more universal capability:
- Diverse Inputs: The system can simultaneously receive and understand data from various sources and formats, such as:
- Text: Medical records, research literature, drug information, etc.
- Image: X-rays, CT scans, pathology slides, dermatological photos, etc.
- Audio: Patient consultation recordings, heart and lung sound auscultation records, etc.
- Video: Surgical recordings, endoscopic examination videos, gait analysis videos, etc.
- And More Modalities: Such as sensor data, genomic sequences, etc.
- Flexible Outputs: Based on task requirements, the model can generate meaningful outputs in different modalities, for example:
- Generating comprehensive textual diagnostic reports based on multiple inputs.
- Creating corresponding medical images or 3D models from textual descriptions.
- Transforming key steps from surgical videos into text summaries or voice prompts.
The advantage of this architecture lies in its high adaptability and integration capability, more closely emulating the thought process of human doctors who synthesize information from multiple sources when dealing with complex cases.
The Core Role of Multimodal Large Language Models (Multimodal LLMs)
Within the grand vision of Any-to-Any, Multimodal Large Language Models (Multimodal LLMs) play the crucial role of the “brain.”
- Fundamental Capabilities of Large Language Models (LLMs): LLMs themselves have already demonstrated astonishing abilities in natural language understanding, semantic reasoning, and text generation. They can comprehend complex medical terminology, contextual relationships, and produce fluent, coherent text.
- Fusing Multimodal Information: The key to Multimodal LLMs is how they “project” information from different modalities into a unified semantic space, allowing the LLM to understand and correlate this information.
- Input Side: For non-textual data like images, audio, and video, specialized Encoders (e.g., Image Encoder, Audio Encoder, Video Encoder) first convert them into feature representations that the LLM can understand. These features then pass through an Input Projection layer to align with text features.
- Output Side: If non-textual output (like an image) is required, the internal representation generated by the LLM passes through an Output Projection layer and is then handed over to specialized Generators/Diffusion Models (e.g., Image Diffusion, Audio Diffusion) to be converted into the target modality.
Exploration and Practice at BIT Research Alliance
At BIT Research Alliance, we don’t just stop at theory; we are committed to applying Any-to-Any and Multimodal LLM architectures to solve real-world medical challenges:
- Improving Diagnostic Accuracy: By fusing patient image data, textual medical history, and lab results, our models can assist doctors in making more comprehensive judgments, reducing the risk of missed and misdiagnoses.
- Personalized Treatment Plans: Combining multimodal information such as genetic data and lifestyle habits, AI can help develop more targeted personalized treatment and rehabilitation plans.
- Intelligent Medical Documentation: Automatically generating structured medical reports from multi-source information or converting complex medical images into easily understandable textual descriptions significantly reduces the documentation burden on healthcare professionals.
- Advancing Medical Research: Mining new correlations and discovering potential biomarkers from massive multimodal medical literature and data accelerates the progress of medical research.
We believe the development of Multimodal LLMs is at an exciting stage. From LLM-centric Alignment and LLM-based Semantic Understanding to Instruction-following Alignment and ultimately Multimodal Output Generation, every step forward is paving the way for more intelligent and comprehensive medical AI.
Challenges and Outlook
Despite the vast potential, the development of Any-to-Any and Multimodal LLMs still faces challenges, such as acquiring high-quality multimodal medical datasets, effectively aligning and fusing information from different modalities, model computational efficiency, and the interpretability of results.
BIT Research Alliance is actively addressing these challenges. Through continuous technological research and development, interdisciplinary collaboration, and a strong emphasis on data privacy and ethical guidelines, we are dedicated to promoting the safe and effective application of these powerful technologies in the healthcare sector.
Conclusion
The combination of Any-to-Any models and Multimodal Large Language Models provides us with an unprecedentedly powerful framework for understanding and utilizing the increasingly complex data in the medical field. BIT Research Alliance will continue to delve deep into this area, explore its limitless potential, and contribute to creating a new future for healthcare driven by data intelligence—one that is more precise, efficient, and humane.