
【Introduction】
As artificial intelligence interacts more frequently with humans today, a crucial question has emerged: how can we ensure AI’s behavior aligns more closely with human expectations, values, and preferences? H.I.T. (Health, Innovation, Technology)’s “RLHF Reinforcement Learning Group” focuses on utilizing Reinforcement Learning from Human Feedback (RLHF) to meticulously refine and calibrate our AI models, especially in complex and high-risk medical application scenarios. Our goal is to build AI systems that are not only technologically advanced but also capable of safe, effective, and empathetic interactions with humans.
I. Guiding AI Evolution with Human Wisdom
H.I.T. has achieved initial success in applying RLHF technology, particularly in enhancing the interaction quality of Large Language Models (LLMs):
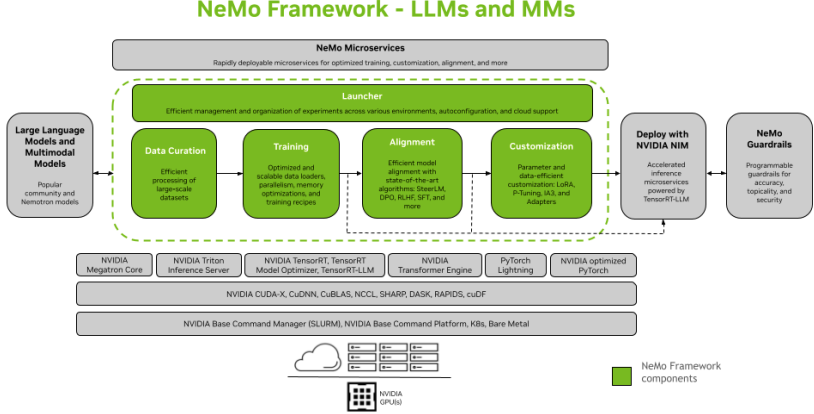

- Improving AI Interaction Alignment and Safety :
- The core idea of RLHF is to enable AI models to learn from human preferences. We train a Reward Model by collecting human ratings, rankings, or modification suggestions for model-generated content. This Reward Model can “understand” what kind of AI response is good, useful, and harmless.
- Subsequently, we use this Reward Model and reinforcement learning algorithms (such as PPO) to fine-tune our foundational AI models (like LLMs). This guides them to generate content that is more likely to receive high rewards, thereby better aligning with human expectations.
- Visual Aid Suggestion: NeMo framework mentions various Alignment algorithms, including RLHF. Although an RLHF process diagram isn’t directly shown, its inclusion in the framework indicates its importance. The “Rewriting and Responding Multi-Agent” (RaR) technology , with its demonstrated improvements in “Enhancement of Professionalism” (14.29% increase) and “Improvement in Readability” (5.81% increase), aligns with RLHF’s goal of making AI output higher quality and more acceptable to humans.
- Reducing Harmful Outputs and “Hallucinations” in AI Models:
- In a field like medicine, which demands extremely high accuracy and safety, RLHF can effectively help us reduce the probability of AI models generating inaccurate information (“hallucinations”) or potentially harmful advice. Through continuous human feedback and iterative model optimization, we can guide models to avoid generating content that contradicts medical common sense or ethics.
- (Reference to latest tech trends): Major AI research institutions are actively adopting RLHF to enhance the safety and reliability of their large models, such as OpenAI’s InstructGPT and ChatGPT.
- Enhancing AI’s Professional Performance on Specific Tasks ):
- Beyond general safety alignment, RLHF can also be used to improve AI performance on specific medical tasks. For instance, we can train models to generate more professional and empathetic doctor-patient communication texts, or to produce medical report summaries that better adhere to clinical guidelines.
- Visual Aid Suggestion: Shows how RaR technology optimized the professionalism and readability of AI-generated content in diabetes and chronic kidney disease (CKD) scenarios. This type of scenario-specific optimization can be guided by human ratings of “professionalism” and “readability” within an RLHF framework.
- Building a Sustainable Closed Loop of Human Feedback and Model Iteration:
- We are establishing efficient processes and tools for collecting, annotating, and managing human feedback data. This feedback is seamlessly integrated into the continuous training and iterative optimization of our models, forming a constantly self-improving AI evolution loop.
II. More Refined, Efficient, and Generalizable RLHF
H.I.T.’s RLHF Reinforcement Learning Group will continue to explore and innovate:
- More Granular and Multidimensional Human Feedback Mechanisms:
- Move beyond simple overall ratings to explore more fine-grained human feedback methods. This includes independent evaluations of specific aspects of AI-generated content, such as factual accuracy, logical coherence, emotional expression, and ethical considerations.
- Research how to fuse human feedback from diverse backgrounds and varying levels of expertise to achieve more comprehensive and balanced optimization directions.
- Improving the Accuracy and Generalization Capabilities of Reward Models:
- The quality of the reward model directly determines the effectiveness of RLHF. We will invest in R&D for more advanced reward model architectures and training methods, enabling them to more accurately capture complex human preferences and generalize to unseen AI-generated content.
- (Reference to latest tech trends): Techniques like contrastive learning and active learning are being used to enhance the data efficiency and performance of reward models.
- Integration of RLHF with Other Alignment Techniques:
- Combine RLHF with Supervised Fine-tuning (SFT), rule-based constraints, and other AI safety technologies (such as Trustworthy AI frameworks) to form a multi-layered AI alignment and safety assurance system.
- Application of RLHF in Multimodal AI Models:
- Extend the application of RLHF from text to multimodal AI models, including images, speech, and video. For example, use human feedback to optimize the quality and realism of AI-generated medical images or to enhance the naturalness and empathy of AI voice assistants in medical scenarios.
- (Reference to latest tech trends): RLHF for multimodal outputs is an emerging and important research direction.
- Exploring Automated or Semi-Automated Human Feedback Acquisition:
- Research how to use AI-assisted tools, or even other AI models, to help filter, preprocess, or simulate parts of human feedback. This aims to improve the efficiency and scalability of the RLHF process while ensuring feedback quality.
III. The Core Competitiveness Empowering Trustworthy AI Applications
RLHF technology is key to building trustworthy, high-quality AI applications, and its commercial value is manifested in:
- Differentiated Advantage of High-Quality AI Models and Solutions:
- In the competitive AI market, AI models meticulously polished through RLHF will possess a significant differentiated competitive advantage due to their higher safety, reliability, and user experience. They will more easily gain customer trust and adoption.
- AI Ethics and Compliance Consulting Services:
- With deep expertise in RLHF and AI alignment, we can provide professional consulting services to other enterprises or institutions, including AI ethics reviews, model safety assessments, and compliance guidance.
- Customized AI Model Alignment and Optimization Services:
- Offer customized AI model optimization services based on RLHF for specific industries or application scenarios (such as finance, law, and education, which have high requirements for content quality and safety).
- Human Feedback Data Platforms and Toolkits:
- Develop and provide efficient human feedback data collection, management, and annotation platforms, along with related RLHF toolkits, to empower other AI developers to implement their own RLHF processes.
- Enhancing User Satisfaction and Brand Loyalty for AI Products:
- Continuously optimizing the interactive experience of AI products through RLHF to better meet user needs can significantly improve user satisfaction and stickiness, thereby building strong brand loyalty.
【Conclusion】
The future of AI lies not only in its power but also in how “human-like” its behavior is—conforming to human values and expectations. H.I.T.’s “RLHF Reinforcement Learning Group” is dedicated to being the bridge connecting the potential of AI technology with the needs of human society. We believe that through human-centered reinforcement learning, we can shape smarter, safer, and more trustworthy AI partners, jointly creating a bright future for human-machine collaboration, especially in the critical field of healthcare.