
Introduction: Pursuing More Powerful and Agile Medical AI
As the wave of Artificial Intelligence (AI) sweeps through the medical field, we are not only pursuing the “intelligence” of models but also placing unprecedentedly high demands on their “efficiency” and “accuracy.” Traditional single, large AI models often face challenges such as enormous computational resource consumption, lengthy training times, and limited generalization capabilities when handling complex medical tasks. To address these issues, an innovative model architecture – the Mixture of Experts (MoE) – has emerged and quickly become one of the key technologies for enhancing AI performance.
BIT Research Alliance is an active explorer and practitioner of MoE technology. We believe that MoE can not only significantly improve the performance of AI models in medical applications but also drive AI technology towards a more universal and efficient direction.
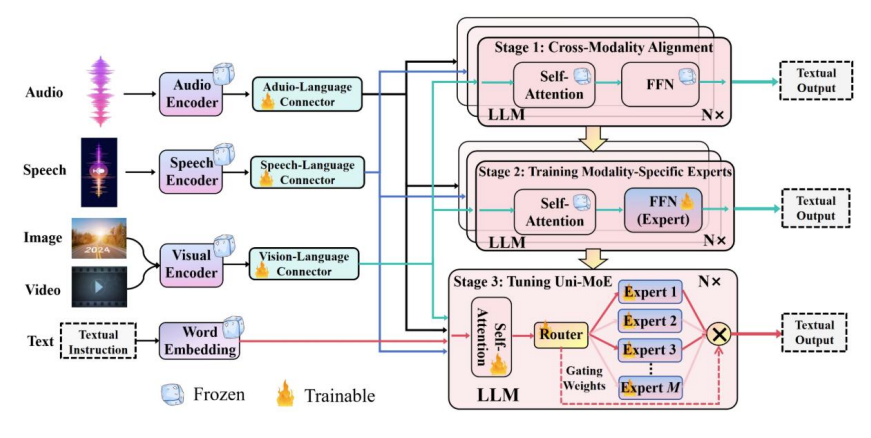
A Deep Dive into MoE (Mixture of Experts)
The core idea of MoE is not to rely on a single “omnipotent” model but to adopt a “divide and conquer” strategy. Its basic architecture includes several key components:
- Multiple “Expert” Models:
- These “experts” are typically relatively smaller, simpler neural network models.
- Each expert may specialize in processing specific types or sub-tasks of data. For example, in a multimodal medical diagnostic system, some experts might focus on analyzing texture features in X-ray images, while others might excel at interpreting keywords in pathology reports.
- A “Gating Network”:
- The gating network is the “dispatch center” of the MoE architecture. Its role is to dynamically decide which expert(s) should process the incoming data based on that data.
- The gating network generates a “weight” or “probability” for each expert, representing how suitable that expert is for processing the current input.
- Combined Output:
- The final output is usually a weighted average of the outputs from all (or selected) expert models, with the weights determined by the gating network.
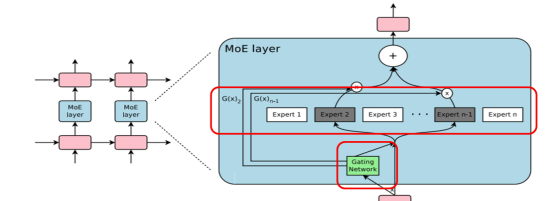
How Does MoE Enhance AI Performance?
The MoE architecture achieves significant performance improvements primarily due to the following reasons:
- Parameter Efficiency: Although an MoE model might contain a large number of “total parameters” (the sum of all expert parameters), only a subset of experts is “activated” by the gating network when processing a single input. This means the “active parameters” involved in computation are far fewer than the total parameters, drastically reducing computational costs and memory consumption.
- Supporting Evidence: The Mixtral 8x7B model has 45 billion total parameters, but only 12 billion active parameters. This allows the model to maintain powerful capabilities while being more hardware-friendly.
- Specialization: Each expert model can focus on learning and processing data features or sub-tasks it excels at, thereby achieving higher accuracy and learning efficiency. In contrast, a single large model needs to handle all aspects simultaneously, which can lead to blurred learning objectives or diluted capabilities.
- Faster Training and Inference Speeds: Due to the reduction in active parameters, MoE models are generally faster to train and run (inference) than dense models of comparable total size.
- Greater Scalability: The capacity of an MoE model can be relatively easily expanded by increasing the number of experts, without needing to train a much larger dense model from scratch.
BIT Research Alliance’s MoE Application Examples in Healthcare
At BIT Research Alliance, we have successfully applied MoE technology to several medical AI projects with encouraging results:
- Multimodal Medical Data Analysis: When processing complex medical data containing multiple modalities such as images, text, and physiological data, the MoE architecture allows different experts to handle their specialized modalities effectively. The gating network then integrates their judgments, improving the accuracy of comprehensive diagnoses.
- Improving the Efficiency of Large Language Models: We are exploring the integration of MoE structures into Large Language Models (LLMs) for tasks like medical text generation and medical Q&A. This allows the models to maintain strong language understanding and generation capabilities while significantly reducing computational overhead.
- Optimizing AI-Assisted Diagnostic Systems: In AI-assisted diagnostic systems, MoE can dynamically select the most suitable expert analysis modules based on the characteristics of the input case, thereby improving the sensitivity and specificity of diagnosing particular diseases.
Challenges and Future Outlook for MoE Technology
Despite its many advantages, MoE also presents some challenges in practical application, such as:
- Gating Network Design and Training: Designing an efficient gating network that can accurately assign tasks is crucial for MoE success.
- Load Balancing: Ensuring that all experts are utilized reasonably, avoiding situations where some experts are overloaded while others are idle.
- Training Complexity: Compared to traditional models, the training process for MoE may require more fine-tuning and sophisticated strategies.
BIT Research Alliance is continuously investing R&D efforts to overcome these challenges and further optimize MoE architectures and their training methods. We believe that as the technology matures, MoE will play an even greater role in:
- More Efficient Edge Computing Medical AI: Reducing model dependency on cloud computing resources, enabling powerful AI functions to be deployed directly on medical devices or mobile platforms.
- Faster Iteration of Personalized Medical Models: Enabling quicker training and adjustment of specialized AI models for specific patient populations or rare diseases.
- Driving More Complex Multi-Task Medical AI Systems: Allowing a single AI system to handle multiple related but distinct medical tasks simultaneously.
Conclusion: MoE — Key to Empowering Efficient and Precise Medical AI
The Mixture of Experts (MoE) model, with its unique architecture and significant performance advantages, is becoming a vital force in advancing medical artificial intelligence. BIT Research Alliance will continue to lead innovation in the application of MoE technology in the healthcare sector, contributing our wisdom and strength to elevate global healthcare standards through more efficient, accurate, and scalable AI solutions. We firmly believe that MoE is not just a technical approach but a critical cornerstone for realizing the vision of inclusive, high-quality smart healthcare.